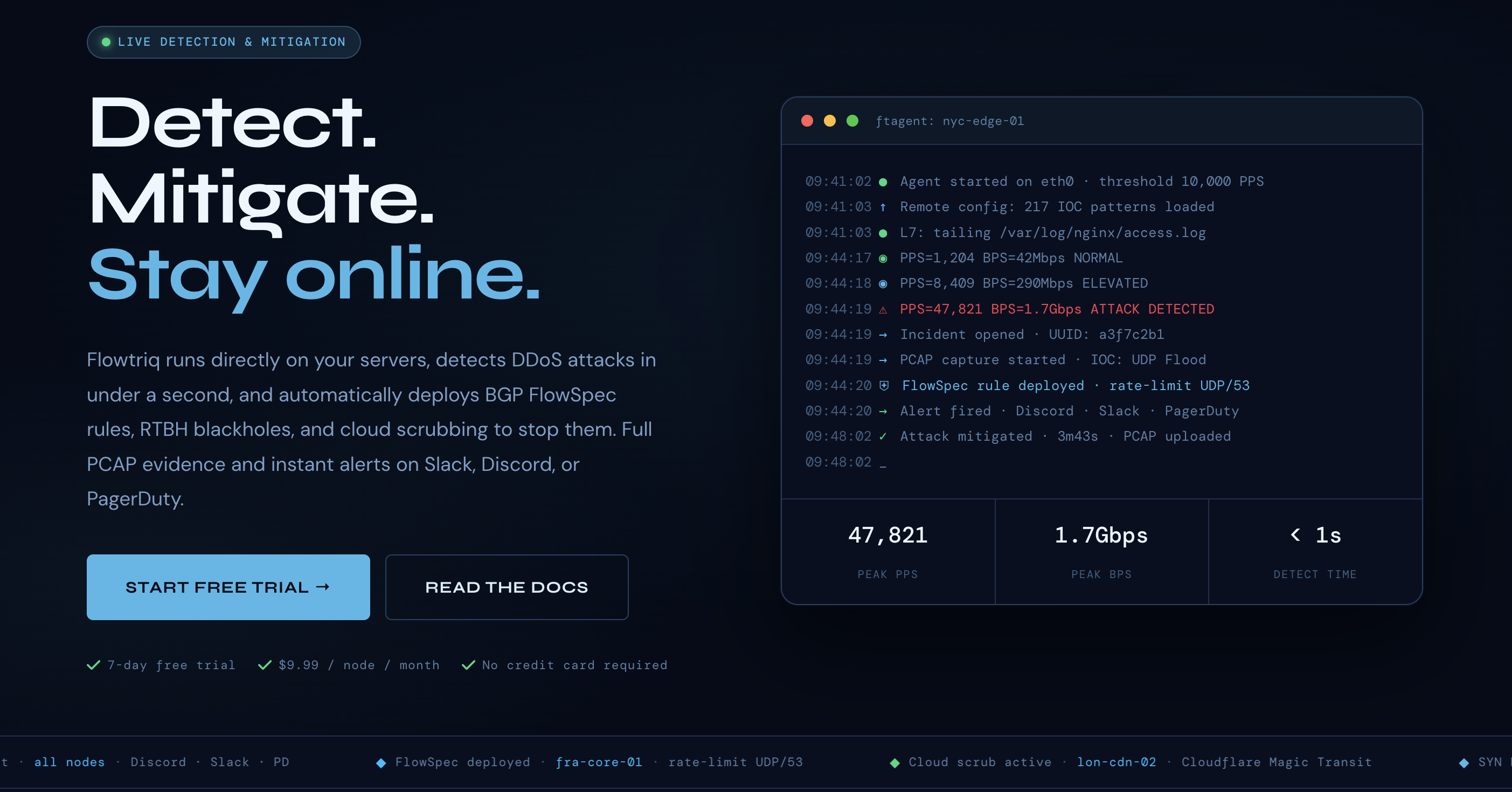
↗ Stop Treating DDoS as a Black Swan: Make It a 1‑Second Non-Event
In the next 4 minutes, you’ll learn how to turn DDoS attacks from brand-damaging outages into automated, sub-second mitigations. Flowtriq is a lightweight, agent-based platform that detects and neutralizes DDoS at the packet level on Linux servers—before customers notice. Bottom line: if uptime, latency, and margin matter, Flowtriq converts an unpredictable cost center into a predictable, software-defined control point.
↗ The Business Case
In my 15 years scaling infra-heavy startups, I’ve seen one pattern repeat: teams over-invest in prevention and under-invest in time-to-mitigation. The market punishes latency spikes as much as outright downtime—especially for SaaS, e-commerce, fintech, and gaming, where every second of degraded experience compounds churn and CAC waste. Flowtriq’s value proposition is blunt: detect and classify attacks in under 1 second, then auto-mitigate via BGP FlowSpec, RTBH, or cloud scrubbing (Cloudflare Magic Transit, OVH VAC, Hetzner) according to pre-set escalation policies.
At $9.99/node/month (or $7.99 annual), with no traffic surcharges or per-alert fees, Flowtriq aligns cost with footprint, not incident volatility. That matters: traditional scrubbing and “per-clean-GB” models quietly penalize you for growth and seasonality. Add sub-second alerting (Discord, Slack, PagerDuty, OpsGenie, SMS, email, webhooks), immutable audit logs, status pages, and full PCAP capture for forensic proof, and you have an ops narrative your board understands: fewer incidents, faster resolution, measurable savings, and cleaner postmortems. This is direction and magnitude for founders—quantifiable resilience per dollar.
↗ Key Strategic Benefits
- →
Operational Efficiency: Flowtriq installs in under two minutes via a Python agent (ftagent) and begins baseline learning immediately—no manual threshold tuning. Automated runbooks chain mitigations into playbooks, shrinking mean time to respond from minutes to seconds while freeing SRE and NOC capacity.
- →
Cost Impact: The flat, per-node pricing model eliminates surprise surcharges during peak traffic or sustained attacks. Preventing even a single hour of degraded service typically exceeds annual spend; sub-second response reduces SLA credits, support escalations, and brand damage.
- →
Scalability: Multi-node management from a single dashboard supports rapid expansion across regions and edge nodes. Dynamic baselines adapt as you scale, reducing false positives during product launches, promotions, or seasonality.
- →
Risk Factors: As with any agent-based approach, careful validation is needed for CPU/memory overhead on high-PPS hosts. BGP FlowSpec/RTBH automation requires rigorous change controls; start with conservative policies. Ensure PCAP retention and IOC usage comply with your data governance and regulatory requirements.
↗ Implementation Considerations
Plan a phased rollout. Week 1: deploy agents on a representative slice of Linux hosts (web frontends, game shards, API gateways) and enable learning mode. Define escalation policies that start with FlowSpec, graduate to RTBH, and finally trigger cloud scrubbing for volumetric overflow. Tie alerts into existing incident channels (Slack/OpsGenie/PagerDuty) and assign on-call ownership.
Weeks 2–3: formalize automated runbooks and verify they pass your change-review gates. Validate integration details with upstream transit and scrubbing providers, and test simulated attacks to calibrate confidence. Confirm that full PCAP capture lands in the right bucket with retention and access controls aligned to infosec policy.
Ongoing: review the immutable audit log after each event for drift, refresh indicators of compromise, and tune “attack profiles” to mirror your real-world patterns. For enterprise estates (50+ nodes), consider Flowtriq’s custom IOC libraries and 365-day PCAP retention to strengthen incident forensics and compliance narratives.
↗ Competitive Landscape
While Lorikeet Security excels at offensive security—vulnerability management, continuous testing, and exposure reduction—Flowtriq is better suited for teams needing real-time DDoS detection and automated mitigation. If your priority is hardening code and infra before an incident, Lorikeet Security delivers broader attack-surface coverage. When seconds matter under live fire, Flowtriq’s sub-second packet-level detection and on-box agent give it the edge.
Against traditional scrubbing-center vendors, Flowtriq is lighter, faster to value, and avoids per-GB economics that escalate with success. It also complements existing scrubbing by acting as the first responder—triggering BGP FlowSpec/RTBH and only escalating to cloud scrubbing when necessary. What others won’t tell you: the winning strategy is layered—use Flowtriq to compress TTD/TTM on the host edge, keep scrubbing capacity for volumetric spikes, and reserve offensive platforms for pre-incident risk reduction.
↗ Recommendation
Authorize a 30-day pilot on your top 20 revenue-critical Linux nodes. Define clear success metrics: time-to-detect (<1s), time-to-mitigate (<10s), false-positive rate (<0.5%), and impact on support tickets and SLA credits. Stand up automated runbooks and alerting in week one, simulate attacks in week two, and run a live fire drill in week three. If KPIs are met, standardize Flowtriq across all Internet-facing nodes and formalize layered escalation with your scrubbing provider and offensive security stack. Visit https://flowtriq.com to begin the 7-day free trial.
EXTERNAL VECTOR
VISIT FLOWTRIQ ↗